Künstliche Intelligenz im Schulalltag: Der EU AI Act und praxisnahe Handlungsempfehlungen
-
KI im Schulalltag
-
Künstliche Intelligenz
Künstliche Intelligenz (KI) bezeichnet Programme oder Systeme, die Aufgaben übernehmen können, für die normalerweise menschliches Denken erforderlich ist. Dazu gehören beispielsweise das Erkennen von Bildern oder Sprache, das Treffen von Entscheidungen oder das Lösen von Problemen.
KI wird zunehmend auch integraler Bestandteil moderner Schulentwicklung.
KI-basierte Chatbots wie ChatGPT, Copilot und Gemini assistieren schon jetzt beim
- Erstellen und Lösen von Arbeitsblättern
- Arrangieren von Lernsituationen
- Verfassen von Elternbriefen
- Erstellen von Grafiken anhand vorgegebener Daten
- Erzeugen von Bildern
- Generieren von HTML-Code samt Inhalt für die Schulhomepage
- ...
Darüber hinaus ist KI schon seit längerer Zeit im Einsatz bei
- Spam-Filtern in E-Mail-Postfächern
- Systemen zur automatisierten Erstellung von Stundenplänen unter Berücksichtigung von Lehrerverfügbarkeiten, Raumressourcen, Schülergruppen
- Texterkennungssystemen (OCR) zur Umwandlung handschriftlicher oder gedruckter Inhalte in digitale Texte für Auswertung, Barrierefreiheit oder Archivpflege
- Spracherkennungssystemen zur Umwandlung von gesprochenen Inhalten in digitale Texte für Auswertung oder Barrierefreiheit
- ...
Arbeitsweise von KI erläutert an zwei Beispielen
Spamfilter
Ein Spamfilter in einem E-Mail-Client wie Mozilla Thunderbird 🔗 basiert auf maschinellem Lernen, einem Teilgebiet der künstlichen Intelligenz. Zur Entwicklung eines solchen Filters wird ein Algorithmus mit einer großen Anzahl vorab klassifizierter E-Mails – sowohl Spam als auch legitime Nachrichten (Ham) – trainiert.
Im Trainingsprozess analysiert der Algorithmus die Inhalte der E-Mails und identifiziert auf statistischer Basis wiederkehrende Muster. Dies erfolgt über Worthäufigkeitsanalysen mittels der Naive-Bayes-Methode 🔗, bei denen bestimmte Begriffe und deren Auftretenswahrscheinlichkeit in Spam- bzw. Ham-Nachrichten berechnet werden. Begriffe wie „Gratis“, „Kredit“ oder „Gewinn“ treten beispielsweise häufig in Spam-E-Mails auf und werden daher im Modell als Indikatoren für Spam gewichtet – allerdings erst nach dem Training. Der Algorithmus kennt diese Wörter nicht im Vorfeld, sondern „lernt“ ihre Bedeutung im Kontext durch die Trainingsdaten.
Ein entscheidender Aspekt ist, dass das System nicht über feste Regeln, sondern über Wahrscheinlichkeiten arbeitet. Es kann daher auch auf benutzerspezifische Trainingsdaten reagieren. Markiert eine Nutzerin oder eine Nutzer beispielsweise regelmäßig dienstliche E-Mails als Spam, weil sie oder er diese nicht erhalten möchten, können auch Wörter wie „Meeting“ oder „Konferenz“ als spamtypisch klassifiziert werden.
Die Fähigkeit, auf Basis von Beispieldaten eigenständig Klassifikationen durchzuführen und sich an neue Muster anzupassen, qualifiziert solche Spamfilter eindeutig als Anwendung künstlicher Intelligenz.
Chatbots mit textgenerierender KI
Die erste ChatGPT-Version von OpenAI, veröffentlicht im November 2022, basiert auf dem Sprachmodell GPT-3.5, einer weiterentwickelten Variante von GPT-3 aus dem Jahr 2020.
Im Zusammenhang mit der Veröffentlichung von GPT-3 hat OpenAI bereits 2020 ein wissenschaftliches Paper 🔗 publiziert, in dem das Training mit den verwendeten Daten dokumentiert ist: Das Modell ist mit frei zugänglichen Textquellen trainiert worden, darunter CommonCrawl 🔗 (60 %), WebText2 (22 %), digitalisierte Bücher (16 %) sowie die englischsprachige Wikipedia (3 %). Letztere allein hat zu diesem Zeitpunkt rund 2,3 Milliarden Wörter umfasst.
Sowohl im Trainingsprozess als auch bei der späteren Nutzung des Modells werden Texte in sogenannte Tokens zerlegt – kleinste Spracheinheiten, die typischerweise aus Wortsilben, Wortteilen oder kurzen Wörtern bestehen. Diese Tokenisierung 🔗 bildet die Grundlage für sämtliche Rechenoperationen im Modell.
Während des Trainings analysiert das Modell große Mengen solcher Tokens, um Muster, Zusammenhänge und Wahrscheinlichkeitsverteilungen zu erlernen. Bei der späteren Anwendung – also wenn eine Benutzerin oder ein Benutzer eine Eingabe macht – generiert das Modell seine Antwort Token für Token. Dabei prognostiziert es jeweils das wahrscheinlichste nächste Token basierend auf dem bisherigen Kontext. Um die Ausgabe natürlicher und weniger deterministisch zu gestalten, wird nicht immer das wahrscheinlichste Token gewählt – gelegentlich wird gezielt ein weniger wahrscheinliches Token ausgewählt, um die Ausdrucksstärke zu erhöhen.
Als Beispiel wird nun die Benutzereingabe (Prompt) „Welche Farbe entsteht, wenn ich Grün und Blau mische?” betrachtet:
- GPT-3 sucht nun das nächste Token basierend auf der Eingabe: „Welche Farbe entsteht, wenn ich Grün und Blau mische? ...”
Mögliche Token, die für GPT-3 in Frage kommen, sind „Die”, „Wenn” und „Falls”. GPT-3 wählt zufällig „Wenn”
Der Text wird um das gewählte Token ergänzt: „Welche Farbe entsteht, wenn ich Grün und Blau mische? Wenn” - Das gewählte Token wird wieder Teil der nächsten Tokensuche: „Welche Farbe entsteht, wenn ich Grün und Blau mische? Wenn ...”
Mögliche Token, die für GPT-3 in Frage kommen, sind „Sie”, „Du”, „wir”. GPT-3 wählt zufällig „Sie”
Die Eingabe wird um das gewählte Token ergänzt: „Welche Farbe entsteht, wenn ich Grün und Blau mische? Wenn Sie” - Das gewählte Token wird wieder Teil der nächsten Tokensuche: „Welche Farbe entsteht, wenn ich Grün und Blau mische? Wenn Sie ...”
Mögliche Token sind „Grün”, „Blau”, „die”. GPT-3 wählt zufällig „Grün”
Die Eingabe wird um das gewählte Token ergänzt: „Welche Farbe entsteht, wenn ich Grün und Blau mische? Wenn Sie Grün”
Dieser iterative Prozess wiederholt sich, bis eine bestimmte Zahl an Token erreicht und dann ein Punkt gesetzt wird.Aufgrund der zufälligen Wahl des Tokens kann man beobachten, dass ChatGPT, das 2022 das verbesserte GPT-3.5 Modell benutzt, bei drei Anfragen mit derselben Frage unterschiedliche Sätze generiert, die sich in Ihrer Aussage qualitativ leicht unterscheiden:
- „Wenn Sie Grün und Blau mischen, erhalten Sie Cyan (auch Türkis genannt), vorausgesetzt, Sie arbeiten mit additiver Farbmischung.”
- „Wenn Sie Grün und Blau mischen, entsteht im Allgemeinen die Farbe Cyan (auch als Türkis bekannt).”
- „Wenn Sie Grün und Blau mischen, ergibt sich in der Regel ein Cyan- oder Türkiston, abhängig vom jeweiligen Mischverhältnis und den genutzten Farbsystemen.”
Dr. Doris Weßels in einem Vortrag über ChatGPT im Ministerium für Schule und Bildung 🔗
Schon diese vereinfachte Darstellung der Funktionsweise von GPT-3 hilft, die nachfolgende Kritik an textgenerierender KI zu verstehen.
Kritik an Chatbots mit textgenerierender KI
In der Veröffentlichung „On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” von Bender et al. (2021) 🔗 wird Kritik an Chatbots mit Sprachmodellen wie GPT-3 zusammengefasst in diesen fünf Punkten geübt:
- Stochastic Parroting
Die Funktionsweise von Sprachmodellen bleibt weitgehend intransparent, insbesondere wenn diese - wie zuvor gezeigt - zufälligen Text generieren. Der Begriff stochastic parrot (stochastischer Papagei) ist dabei eine Metapher, die beschreibt, dass große Sprachmodelle zwar in der Lage sind, plausibel wirkende Sprache zu erzeugen, jedoch die Bedeutung der von ihnen verarbeiteten Sprache nicht verstehen. Bei der Generierung von Text kann es durch die zufällige Wahl des nächsten Tokens zu Halluzinationen und fehlerhaften Aussagen kommen:
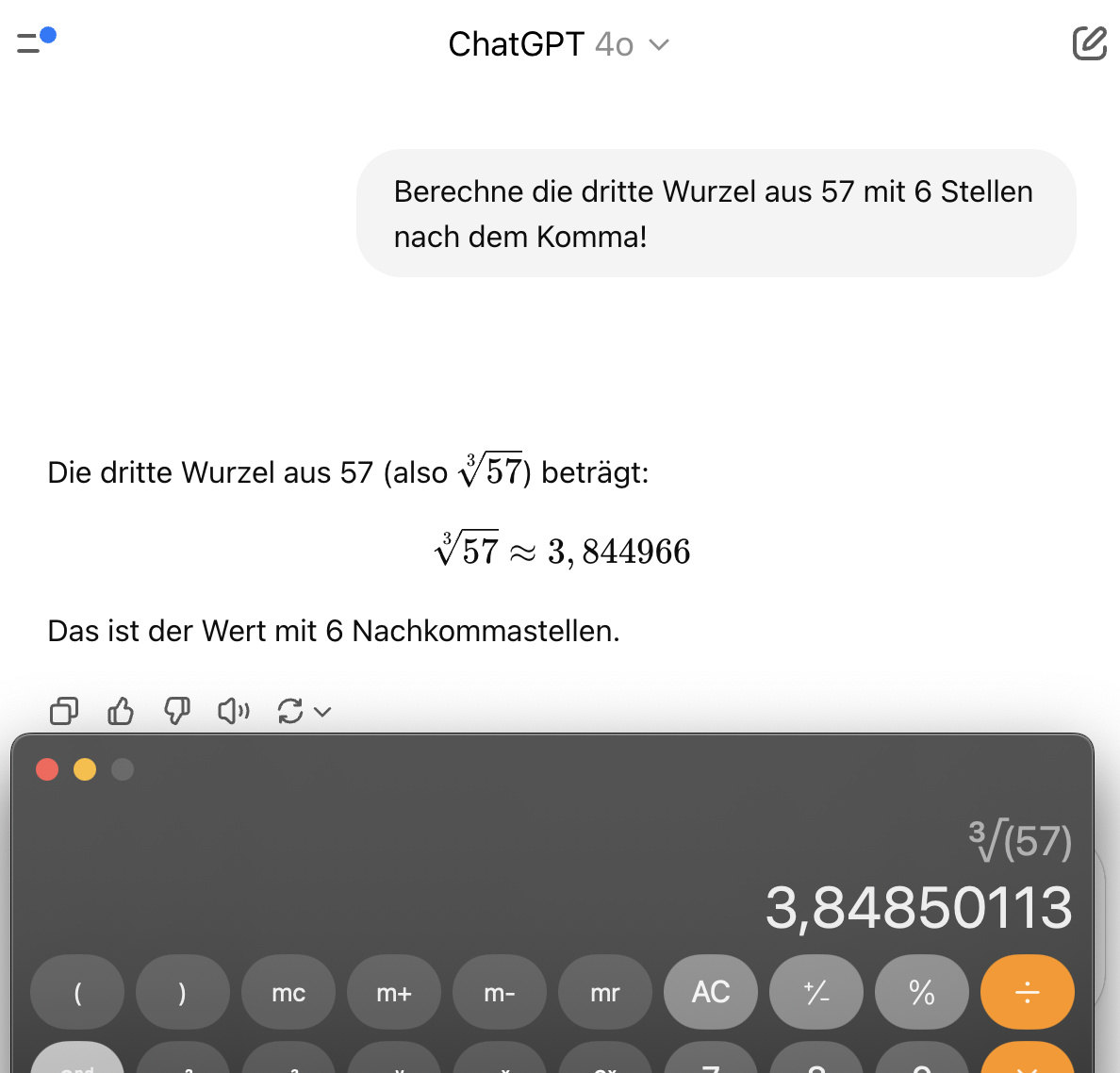
Selbst die neuste Version von ChatGPT gibt die dritte Wurzel aus 57
nicht korrekt an, da diese nicht berechnet, sondern zufällig generiert wird. - Datenschutzprobleme
Große Sprachmodelle werden mit allen allgemein verfügbaren Daten aus dem Internet (z.B. CommonCrawl) trainiert. Dort finden sich auch personenbezogenen Daten. Diese Daten können die Sprachmodelle dann auf Anfrage wiedergeben. - Statische Momentaufnahmen
Sprachmodelle basieren auf statischen Daten, wodurch sie nicht mit gesellschaftlichen Veränderungen Schritt halten können. Der Begriff „value-lock“ wird verwendet, um zu beschreiben, dass veraltete oder exkludierende Weltanschauungen im Modell fixiert werden. - Datenverzerrung
Große Trainingsdaten (z. B. Common Crawl) überrepräsentieren tendenziell hegemoniale Sichtweisen, unterrepräsentieren marginalisierte Gruppen und verstärken so Verzerrungen und Diskriminierungen. Außerdem ist GTP-3 mit überwiegend englischsprachigen Texten trainiert worden, was dann zu Ausgaben mit englischsprachiger, eher westlicher Weltsicht führt. - Umweltkosten
Sowohl das Training als auch die Benutzung eines großen Sprachmodells hat einen enormen Energieverbrauch zur Folge.
Für das Training von GPT-3 geht man von einem CO2-Äquivalent von 552 Tonnen 🔗 aus, dem etwa 100 Äquatorumrundungen mit einem Mittelklassewagen entsprechen.
Über die Umweltkosten einer Benutzeranfrage an GPT‑3 existieren verschiedene Schätzungen – häufig wird die Energie einer Google-Suchanfrage (~0,3 Wh) als Referenz herangezogen. Während verschiedene Medienberichte einen zehnfach höheren Verbrauch im Vergleich zu einer Google-Suche ansetzen, liefert Vanderbauwhede in einer Veröffentlichung von 2025 🔗 eine modellübergreifende Analyse: Demnach benötigen KI-gestützte Suchanfragen – basierend etwa auf GPT‑3‑ähnlichen BLOOM-Modellen – etwa 60‑fach mehr Energie als herkömmliche Web-Suchen.
Seit 2021 hat sich die Landschaft großer Sprachmodelle weiterentwickelt, wobei Fortschritte in verschiedenen Bereichen erzielt wurden:
- Statische Momentaufnahmen
Einige Modelle integrieren jetzt Mechanismen zur Aktualisierung ihres Wissens, z. B. durch Retrieval-Augmented Generation (RAG), wobei aktuelle Informationen aus externen Quellen abgerufen werden. Dennoch bleibt das zugrunde liegende Modell auf dem Stand seiner letzten Trainingsdaten. - Datenverzerrung
Es gibt verstärkte Bemühungen, Trainingsdaten zu diversifizieren und zu kuratieren, um Verzerrungen zu reduzieren. Trotzdem spiegeln viele Modelle weiterhin die Vorurteile ihrer Trainingsdaten wider, was zu problematischen Ausgaben führen kann. - Umweltkosten
Es wurden effizientere Trainingsmethoden entwickelt, wie z. B. sparsames Training und spezialisierte Hardware, um den Energieverbrauch zu reduzieren.
Eine typische Anfrage (Prompt) bei ChatGPT-4o verbraucht nach einer aktuellen Studie etwa 0,3 Wattstunden, mit denen eine 10 Watt LED Lampe für 108 Sekunden betrieben werden könnte.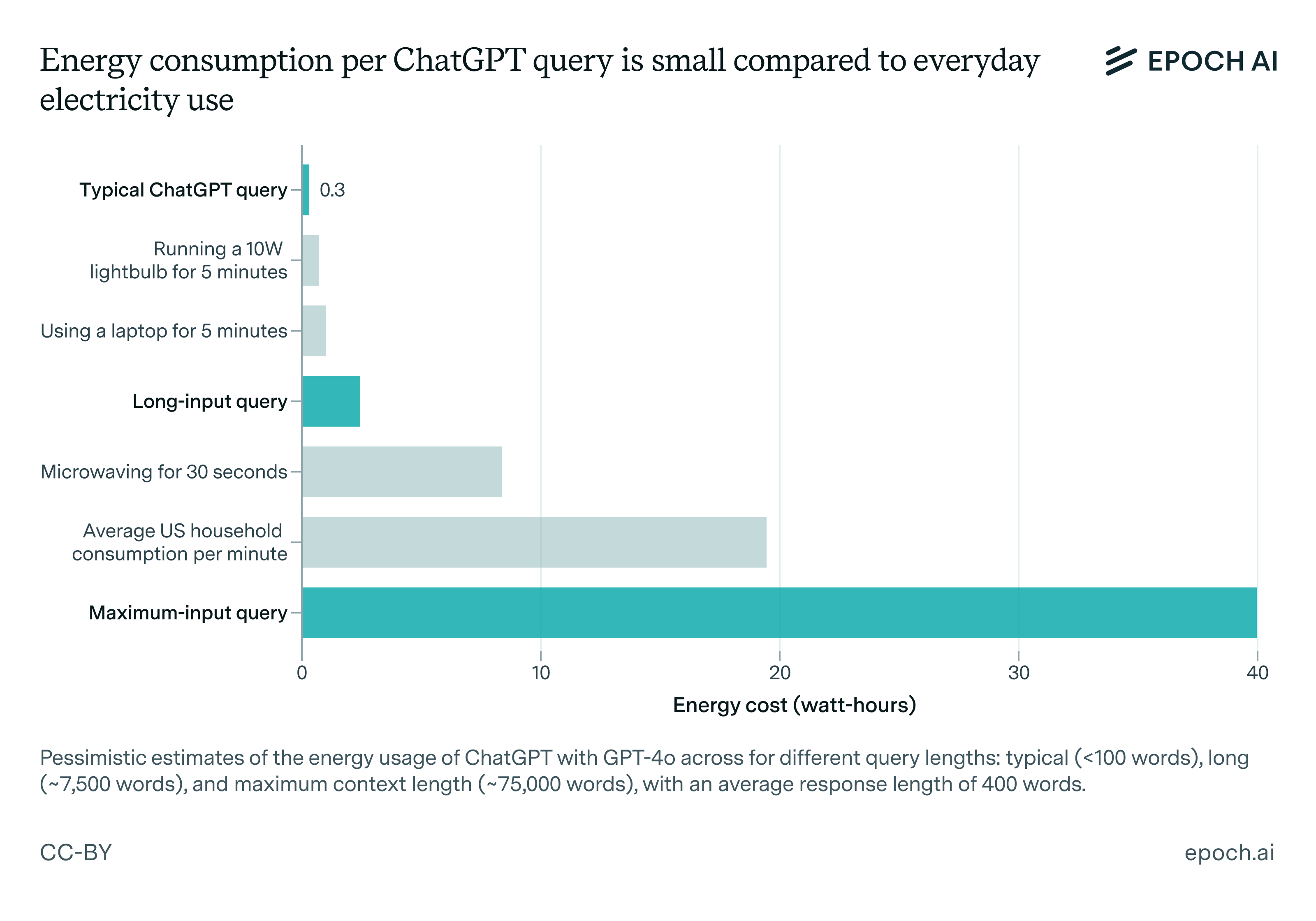
Dennoch bleibt der Ressourcenbedarf für das Training und die Anfragen großer Modelle erheblich. Vor allem wenn man bedenkt, dass ChatGPT nach Angaben von OpenAI 🔗 allein in der EU zwischen Oktober 2024 und März 2025 durchschnittlich im Monat 41,3 Millionen aktive Benutzerinnen und Benutzer hat.
Fazit
Es ist verlockend, KI-Lösungen blind zu vertrauen: Sie generieren sekundenschnell scheinbar sehr fundierte Antworten und greifen auf ein breites Spektrum menschlichen Wissens zurück. Doch genau dieses Vertrauen birgt das Risiko, von KI irreführende Inhalte zu erhalten.
Ein effektiver Schutz entsteht durch transparente Einblicke in die Funktionsweise von KI – insbesondere durch das Verständnis, dass
- KI-Modelle auf Trainingsdaten basieren,
- eine verantwortliche Instanz die Auswahl dieser Daten vorgibt,
- die Datenverantwortlichen dadurch wesentliche Einfluss- und Entscheidungskompetenz besitzen,
- die herangezogenen Trainingsdaten systematische Fehleinschätzungen (Bias) oder Fehler enthalten können.
Diese Erkenntnis löst die Illusion auf, KI sei eine autonome „intelligente Maschine“. Vielmehr handelt es sich um ein strategisches Business-Tool – leistungsfähig, aber nicht allwissend oder unfehlbar.
-